

Hire by Technology
SERVICES


Rule-based fraud detection fails in two predictable ways as fintech scales.
False positive rates rise as transaction volume and user diversity grow, degrading customer experience. And false negative rates rise as fraudsters learn the rule boundaries and route around them.
Financial applications hinge heavily on user trust. Even the tiniest mistake can be enough to lose clients to your competitors. On top of that, the industry is heavily regulated, and leaving gaps for failures like this leads to costly fines.
The shift to ML-based fraud detection architecture for fintech solves both problems, but only if done correctly.
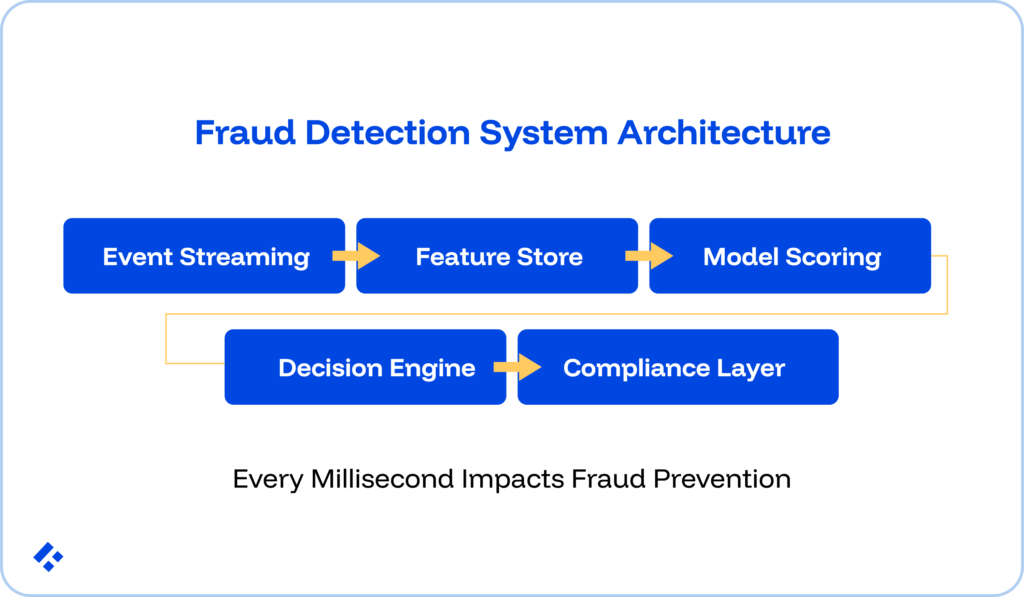
Let’s look at the five-layer fraud detection architecture that helps you avoid as many failure modes as possible, and set your company up to scale rapidly without sacrificing compliance.
At Trio, we have pre-vetted fintech compliance engineers with production experience in a variety of different financial applications, who can be placed in as little as 3-5 days.
Each of the layers in a production-grade fintech fraud detection system has its own engineering domain, tooling choices, and failure modes.
Each of these layers carries a latency budget that must be designed against from the start.
The pipeline entry point sets the latency floor for everything downstream.
This is why it is so critical that you get the streaming topology right. Mistakes here make it nearly impossible to recover the sub-100ms SLA at later layers, regardless of how well those layers are optimised.
Apache Kafka is still the standard for high-throughput, low-latency event streaming in fintech fraud detection. It offers configurable partitioning, like partitioning by user ID, which maintains per-user event ordering.
This matters specifically for velocity feature computation at sub-10ms end-to-end latency with appropriate broker configuration, and durable message retention that allows replay for feature backfill and model retraining.
AWS Kinesis might be a good option if your fintech is fully AWS-native, and where the operational overhead of managing a Kafka cluster isn't justified at the current scale.
Apache Pulsar handles multi-tenancy and multi-region deployment patterns well, but carries higher operational complexity and a smaller available talent pool.
The ultimate goal is to prevent event loss under load.
The streaming platform must be configured with appropriate replication and retention policies so that a broker failure doesn't create gaps in the feature store's historical record.
Gaps in historical data corrupt velocity features and degrade model performance without ever surfacing as an obvious error.
Your latency budget here is about ≤10ms from transaction event to stream availability for downstream consumers.
Related Reading: Elevating Customer Experience for Fintech Companies
From what we have seen, the feature store is the most architecturally consequential layer in the fraud detection system.
Every other layer depends on it.
Unfortunately, it is also where the most common and costly production failure originates.
Training-serving skew happens when the features used during model training differ from the features available at inference time. We see this all the time when detection systems are built without a purpose-built feature store.
The most common cause we see is when velocity features computed during offline training use a complete historical view (all transactions for a user across the full training dataset), while the same velocity feature computed at inference time uses only a 1-hour rolling window.
A purpose-built fraud feature store maintains two distinct data paths:
Write path (training): A batch processing pipeline materialises features from historical transaction data, which are stored with timestamps to allow point-in-time correct lookups.
This makes it possible to train on features as they exist at decision time.
Read path (inference): A low-latency serving store (Redis or DynamoDB) holds the most recent feature values for each user or entity, pre-computed by a streaming job consuming the event stream.
Inference reads from this serving should store synchronously on the critical path.
The Population Stability Index (PSI) measures the distributional shift between training and production feature distributions.
Anything above 0.2 signals meaningful drift and should trigger a documented review. PSI above 0.25 should trigger retraining evaluation.
These thresholds must feed into the SR 11-7 ongoing monitoring record, with a queryable log of when each comparison ran, what the value was, what action was taken, and who approved it.
Your latency budget here should be ≤15ms for feature retrieval from the serving store (Redis or DynamoDB single-digit millisecond reads with appropriate provisioning).
Fraud prevalence in fintech transaction datasets typically sits at 0.1–2% of all transactions.
This means that even a model that classifies every transaction as legitimate achieves 99%+ accuracy while catching zero fraud, making accuracy a useless metric.
SMOTE (Synthetic Minority Oversampling Technique) generates synthetic fraud examples to balance the training dataset.
However, applying SMOTE to validation data is a common mistake that produces optimistic offline metrics and then fails in production.
Cost-sensitive learning is another way to handle class imbalance. It assigns asymmetric misclassification costs directly into the model's loss function, so the model optimises toward catching fraud even at the expense of some false positives.
Threshold calibration is another great tool, and it adjusts the decision boundary away from 0.5 toward the precision-recall tradeoff that matches the product's actual risk appetite.
Gradient-boosted decision trees (XGBoost, LightGBM) are the production standard for tabular fraud detection. They handle heterogeneous feature types, produce feature importance scores compatible with SHAP explainability, and run inference in under 5ms on CPU.
All of this is important to think about for your latency budget.
Neural approaches (LSTM for temporal patterns, Graph Neural Networks for fraud ring detection) work as supplementary models in an ensemble because their inference latency runs 10–50ms.
You then combine the multiple different model outputs through a meta-scorer or weighted vote to reduce false positive rates while maintaining recall.
Your latency budget for this entire model scoring layer should be ≤20ms.
A fraud risk score is nothing more than a probability estimate.
The decision requires that score to combine with deterministic rules encoding business policy, risk thresholds calibrated to the product's risk appetite, and escalation logic that routes uncertain cases to step-up authentication or human review.
This layer is the one we see missing a lot in under-architected fraud systems.
When it's absent, business logic gets baked into the ML model instead. This looks good on the surface, but it conflates two separate problems and makes both harder to maintain.
Tier 1 is made up of deterministic rules (pre-model). These are hard-coded checks that run before model scoring because they're never ambiguous (sanctions screening matches, cards reported stolen, and accounts flagged by law enforcement). They're hard declines.
Tier 2 is your model-scored risk bands. The ML risk score determines routing:
Tier 3 is your human review queue. Transactions that Tier 1 and Tier 2 can't resolve enter a queue for fraud analyst review. The analyst’s decisions feed back into the training pipeline as confirmed fraud labels, closing the supervised learning feedback loop.
Your total latency budget for this layer should be ≤15ms.
SR 11-7 (Federal Reserve and OCC model risk management guidance) requires that AI models influencing financial decisions be documented with their purpose, assumptions, and limitations.
Along with that, they need to be independently validated, continuously monitored for performance degradation, and subject to human override with documented escalation procedures.
In fintech specifically, this translates to four specific engineering deliverables.
Every model scoring decision must produce an append-only audit record.
This should include a timestamp (millisecond precision), model version, the feature vector input to the model, the raw risk score, the threshold configuration active at decision time, the final decision (approve/decline/step-up), and the customer or transaction identifier.
The important thing is that this record is queryable by regulators and internal auditors.
For any transaction declined or stepped-up, the system must produce an explanation of the top contributing features.
This satisfies SR 11-7's interpretability documentation requirement and ECOA/FCRA adverse action notice requirements where the fraud flag influences credit-adjacent decisions.
The biggest problem for production teams is that SHAP computation adds 10–50ms to inference latency.
The solution is an async SHAP pattern.
PSI computed on key features triggers alerts and retraining evaluation.
The monitoring pipeline must log these comparisons as SR 11-7 ongoing monitoring evidence.
As we have already mentioned, this needs to include a queryable record of when the comparison ran, what the PSI value was, whether it breached the threshold, what action was taken, and who approved it.
Every model in production must be registered with its training data hash, feature list, evaluation metrics (including AUPRC and FPR at the deployed threshold), independent validation results, and deployment approval history.
This sounds like a lot, but when a regulator asks which version of the fraud model was scoring transactions on a specific date and what data it was trained on, the model registry must answer that question without manual reconstruction.
Your latency budget here should be ≤5ms.
These problems span all five layers, and they are also the ones that we most often see surfacing after deployment, rather than during design.
A big reason for this is that they require fintech ML engineering experience to anticipate, which many growth-stage fintechs don’t keep on hand.
Everything you build either creates or prevents training-serving skew.
We have already discussed how the feature store prevents it. Drift monitoring in your compliance layer catches it when it emerges post-deployment.
If your team doesn’t have prior fintech ML experience, they will probably only discover this problem when production precision-recall diverges from offline metrics.
The most common failure pattern that we see is when a capable ML model gets trained and deployed without the regular compliance infrastructure in place.
If you have no SR 11-7 documentation, no drift monitoring, and no audit log, you may be at risk of fines or other backlash.
Retrofitting these after the model is already scoring production transactions costs significantly more, and increases the chances of mistakes or integration difficulties, than building them in parallel.
But, by far the greatest difficulty our developers have come across is the fact that the audit log requires the model to emit feature vectors at inference time, and if your model is not instrumented for this, it can't be retrofitted without a full redeployment.
This is one of many reasons why a security-first culture in fintech is essential.
The threshold where a risk score triggers a decline is a business decision that needs to be owned by the fraud operations team, documented in the model registry as a versioned configuration, and revisited when fraud patterns change.
If your team that bakes the threshold into the model for some reason conflates the ML problem with the business policy problem, it is guaranteed to end badly.
The fraud ops team needs to adjust sensitivity without a model retraining cycle.
A production fraud detection system at a fintech company involves many different disciplines. The reality is that these skillsets are rarely present in the same people. Here are all the skills that we recommend if you want to set yourself up for serious growth:
Fraud detection in fintech isn't one engineering problem, but several separate issues, and they have to be designed correctly and integrated correctly.
The architecture described above is the path to a fraud detection system that keeps working as transaction volume scales, as fraud patterns evolve, and as regulatory scrutiny increases.
If you are assessing whether your current AI integration posture is ready to facilitate that kind of scale, your regulatory compliance infrastructure is usually the clearest signal of whether the system was built for production or built for demo.
If you need to hire fintech developers with ML, data engineering, and compliance depth to build an effective fraud detection system architecture for your team, we can place our pre-vetted developers in as little as 3-5 days.





