Hire by Technology
SERVICES


When a payment system fails, people notice immediately.
A small hiccup that stops a transaction for even a few seconds may look harmless on paper, but in the moment, it creates real anxiety for the user who just wants their card to work.
For a business, it often means lost revenue, a support ticket, and a little less customer trust than before. As payment processing grows more complex and increasingly real-time, these small failures tend to add up.
What makes this tricky is that a modern payment platform sits on top of a mesh of critical systems. You rely on networks, issuers, acquirers, payment gateways, and third parties.
Any one of them can slow down or create a single point of failure. Without high availability baked into the architecture, you end up reacting to problems instead of preventing them.
The encouraging part is that you can design a highly available and genuinely resilient processing system when you place reliability, uptime, and scalability at the center of your choices. Our fintech developers here at Trio can help you do that.
But before you jump into hiring expert fintech developers, let's make sure you understand the intricacies of high-availability payment systems.
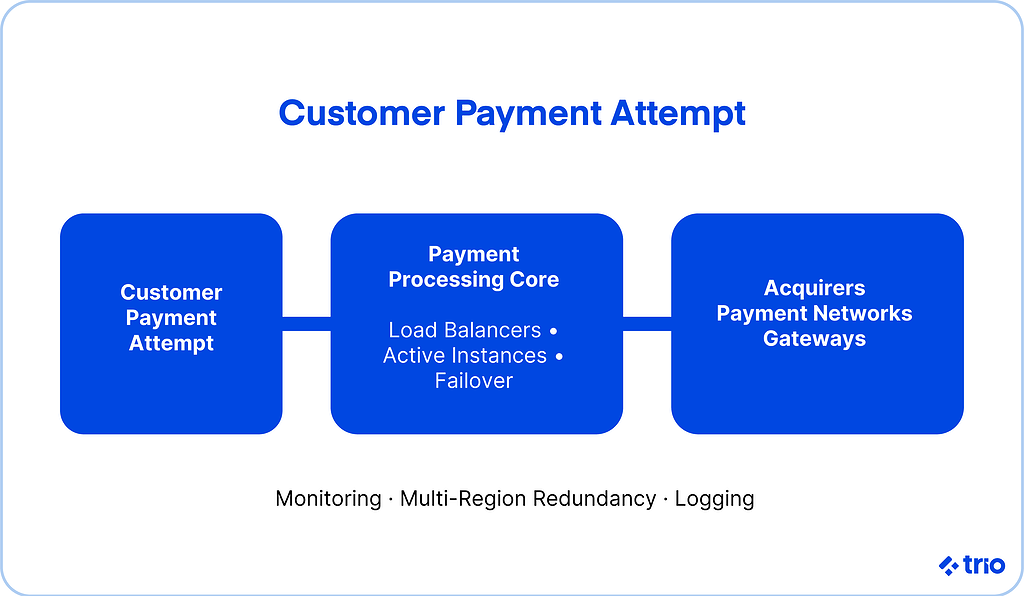
A reliable payment system is more than an engineering preference. It is the quiet backbone that keeps e-commerce, subscription billing, and in-person transactions running without interruption.
When high availability drops, downtime becomes real money lost.
The moment a transaction stalls or fails, the customer experience suffers. People have very little patience during checkout, and even less when they are unsure if their card was charged.
The harm spreads wider than the initial incident, since the customer may think twice about returning.
High uptime is not simply a performance goal. It is a financial one.
Financial institutions, payment gateways, and modern payment services operate under strict expectations for uptime and data protection.
Regulations around PCI DSS compliance, KYC, and AML tend to raise the baseline.
At the same time, global payment processors like Visa and UPI have pushed expectations higher by proving that extremely high availability is achievable.
For any business handling payment transactions at scale, the bar is now much higher than it used to be.
Most teams hear the phrase high availability and picture a system that never breaks. In reality, the goal is slightly different.
A highly available processing system is built so the user rarely notices failures, even when components break behind the scenes.
Related Reading: Payment Facilitation (PayFac) Explained
High availability is usually defined by an availability SLA such as 99.9, 99.99, or 99.999 percent uptime.
These might sound abstract at first, but the numbers translate to very real expectations.
An SLA of 99.99 percent lets you have a few minutes of downtime per month. Once you reach the mission-critical threshold of 99.999 percent, the allowed interruptions shrink to seconds.
Absolute perfection is unrealistic, but the idea is to remain operational and accessible even when parts of the system become unreliable.
Reliable payment processing depends on layers of protection.
Taken together, these patterns reduce the chance of a disruption reaching the customer.
A payment processing system needs an architecture capable of handling millions of transactions under unpredictable conditions.
Designing for high availability early avoids expensive fixes later.
When payment transactions spike or an acquirer slows down, problems spread quickly. High-volume transactions put pressure on networking, validation workflows, and settlement paths. It may also introduce odd consistency problems.
For example, you might see a payment authorization succeed, but the clearing step gets delayed due to data replication issues.
These situations are common in extremely high-traffic systems and deserve attention before you grow.
Horizontal scaling is often the simplest path forward because it spreads your workload across multiple servers.
Active systems are common in payment gateways because they let you process transactions simultaneously across regions.
Event-driven architecture helps isolate workflows so that failures in one part of the payment platform do not ripple into others.
Each of these choices comes with tradeoffs, of course, but they tend to push reliability in the right direction.
A healthy processing system adjusts at the edge. Load balancing distributes traffic across available instances and avoids routing users into a bottleneck.
Health checks give you early signals when a gateway or region begins to degrade. It may look like a small operational detail, yet it often saves you from a major outage.
Redundancy gives you breathing room. With N+1 capacity, your system can keep running even if a node fails.
Multi-region deployment protects you when an entire data center or availability zone encounters problems. Cross-region data replication ensures consistency, although it can add latency if designed poorly.
Still, it is one of the more reliable ways to avoid catastrophic downtime.
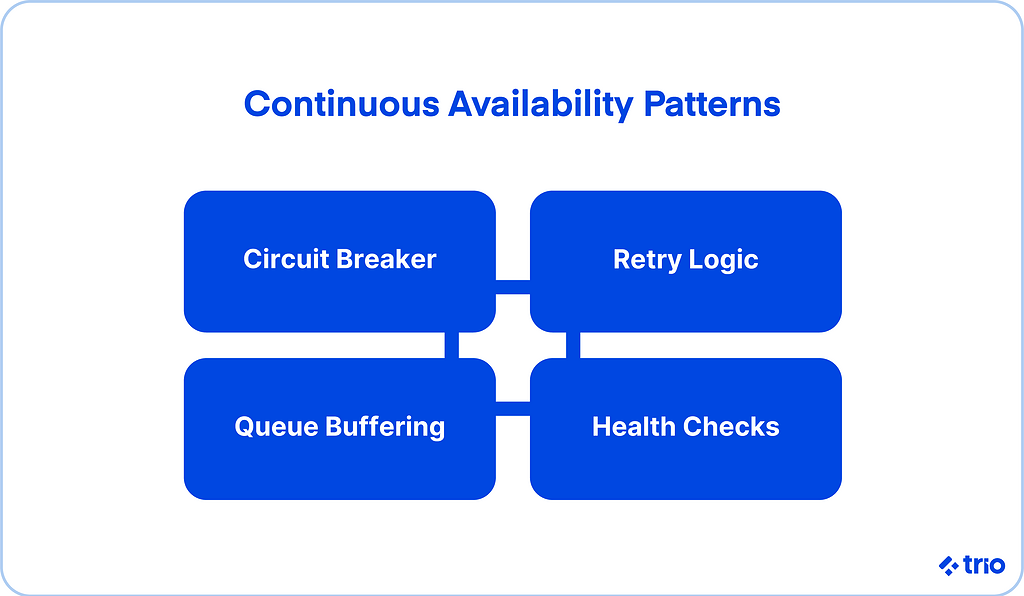
When you aim to process payments reliably, small design patterns become powerful tools.
Circuit breakers can cut off a failing downstream service before it drags everything else down. Queues smooth uneven workloads. Retry logic helps recover from transient network issues.
None of these solves downtime alone, but they create a safer baseline when combined.
Your routing logic and API design often determine how well your system handles failures from external payment services.
These layers may appear simple, but they carry a large share of responsibility for high availability.
A modern payment gateway often talks to multiple acquirers and services.
An API-driven payment platform benefits from stability more than anything else.
Idempotency prevents duplicate charges when clients retry a request. Versioning supports long-lived integrations without breaking them during updates. Timeouts and retries help balance customer experience and system protection.
These might seem like small API details, but they often make the difference between seamless payments and visible failures.
Architecture alone cannot guarantee uninterrupted service.
A payment processing system needs an operational culture that treats reliability as an ongoing practice.
Real-time observability gives you visibility into latency, workload patterns, and odd behaviors that may suggest upcoming system failures.
Traces help you understand exactly where a transaction slows down. Logs provide context when workflows misbehave.
When you operate a mission-critical processing solution, early signals are priceless.
Site Reliability Engineering shapes how many modern payment platforms work.
Error budgets help you balance shipping features against creating risk. Runbooks guide teams under pressure. Post-incident reviews help you reduce the chance of repeating the same outage.
The practice is not perfect, but even lightweight adoption helps maintain high uptime.
PCI DSS compliance, firewalls, and careful handling of sensitive data all support long-term reliability. Breaches create downtime.
Weak authentication or missing KYC and AML controls can slow payment workflows. In the context of payment transactions, security and uptime tend to reinforce each other rather than compete.
Looking at the habits of major payment providers offers a clearer picture of what works in the real world.
Companies such as Visa, Adyen, and Stripe rely on multi-region deployments, aggressive health monitoring, and traffic shaping techniques that constantly adjust.
They often build custom routing and orchestration layers to handle changes across multiple regions.
Outages happen to nearly everyone, even highly experienced teams.
Common issues include routing mistakes, data replication delays, or unexpected surges from e-commerce partners.
The teams that recover quickly tend to focus on transparency, careful analysis, and long-term fixes.
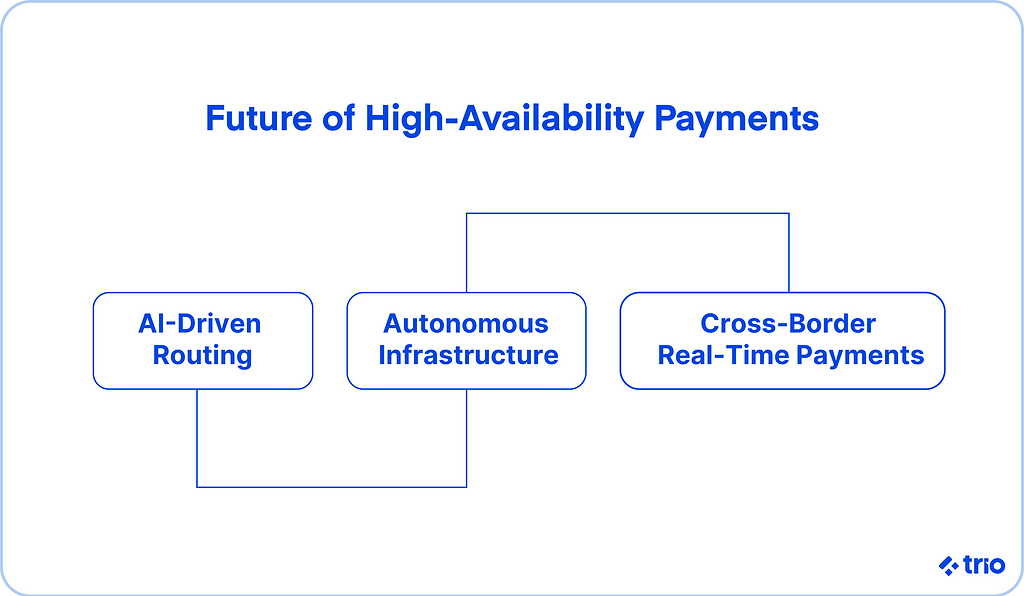
The landscape around payment processing is shifting quickly.
Some trends may seem experimental today, but are likely to influence the next generation of payment solutions.
AI has already become part of many routing workflows. It appears especially promising for identifying patterns that signal an upcoming slowdown.
With enough data, a system may proactively route payments away from deteriorating providers.
Some teams are testing systems that adjust capacity and routing on their own.
While still early, this direction could reduce manual intervention during high-volume transactions.
As ISO 20022 adoption spreads and real-time networks grow, more transactions will rely on consistent latency across multiple regions.
Keeping these rails reliable without high operational complexity is becoming a larger challenge.
Distributed systems and blockchain-based settlement models may offer alternative workflows where data loss is harder to achieve, and transaction settlement becomes more predictable.
A scalable and highly available payment system does not happen accidentally. It is the result of deliberate choices in system architecture, routing, APIs, and day-to-day operations.
When you build for reliability early, you give your business room to grow without interruption. You safeguard customer trust and reduce the risk of painful downtime.
And you help your payment platform process transactions smoothly, regardless of what the underlying networks decide to do on any given day.
To find expert fintech developers who can ensure your systems are built for availability and long-term scalability, get in touch!
High availability in a payment system refers to keeping the platform operational even when parts of the infrastructure fail, so users can process payments reliably at all times.
High availability matters for payment processing because downtime interrupts transactions, reduces customer trust, and leads directly to lost revenue.
A payment system reduces downtime by using redundancy, failover mechanisms, load balancing, and continuous monitoring to detect and avoid failures.
A payment system is scalable when it can handle increasing transaction volume through horizontal scaling, multi-region design, and efficient traffic distribution.
High-volume transactions affect system reliability by stressing network paths and workflows, making latency and bottlenecks more likely without proper architecture.
API design plays a role in high availability by using idempotency, proper timeouts, retries, and versioning to protect clients during failures.
Redundancy is important in a payment gateway because it prevents a single point of failure from disrupting large groups of transactions.